Embodied AI: The Data Bottleneck
Introduction
The deep learning research community following AlphaGo in 2015 was convinced that reinforcement learning was the next paradigm to solve towards building AGI and superhuman capabilities.
OpenAI invested heavily into research on RL and robotics in its early days, but later pivoted into focusing on unsupervised learning with RL being “the cherry on top”1.
However one of the early projects lost between the ashes is “World of Bits” proposed by Andrej Karpathy:

The idea was that in order to build a general purpose model that can control computers and do human economically valuable tasks, you’d want to use RL on solving general tasks instead of optimizing for specialized games like Go and that solving this would be a big milestone towards building AGI.
For a lot of reasons this project didn’t go too far towards building a general purpose computer agent, and it was only after unsupervised learning with Generative Pre-trained Transformers (GPTs) was solved that we’re now seeing projects like OpenAI Operator or Ace successful at this task.
Embodied AI
Embodied AI is best defined as an AI agent that can make observations and take actions in either the digital or physical world. Lots of progress has been made on embodied AI for the digital world, and for a lot of reasons I think that it won’t be the hardest problem to solve2.
One of the early works of embodied AI in the physical world was imitation learning from the “End to End Learning for Self-Driving Cars” project at Nvidia where they did supervised learning on human “expert” data to learn how to steer the wheel based on vision:
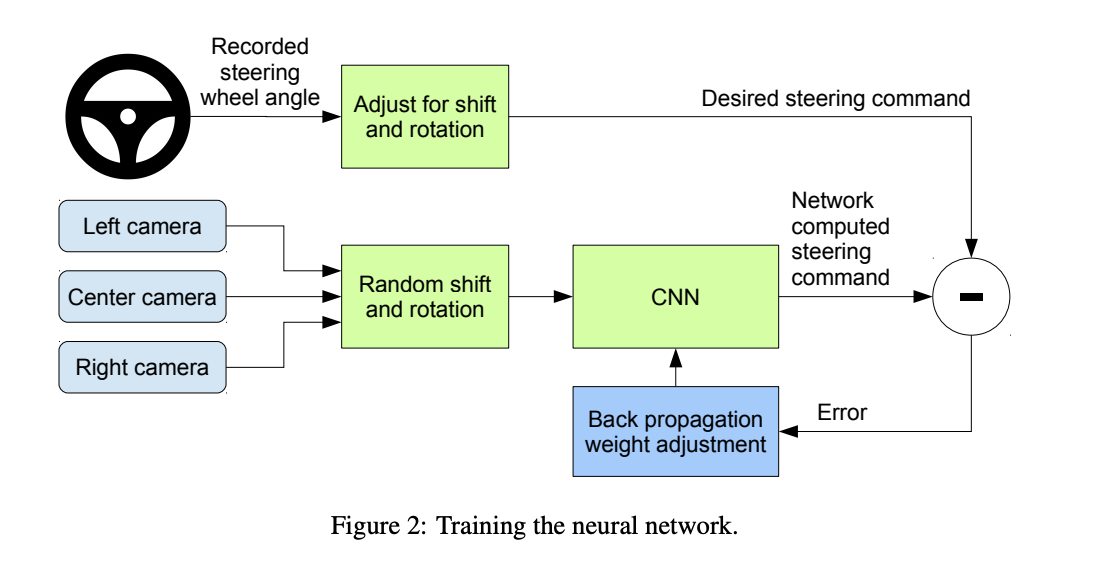
This is basically the approach that Tesla has taken to build it’s autopilot FSD, by taking this simple idea to its maximum in terms of data collection plus shadow mode where they collect edge cases of when humans intervene and take a different action than their model.
Imitation learning works really well for driving, as well as for computer control agents like Ace:
While other organizations tried to learn to drive via a world model like Comma AI to provide better on-policy learning, both approaches combine some form of behavioural cloning with on-policy learning.
Now that we’re in the era of humanoids, these methods are their learning boundaries!
Cars operate on flat roads, with 2 DoF (steering angle + forward/backward) i.e have four basic action outputs: steer left, steer right, gas, brake. Humanoids, on the other hand have at least 28 DoF (10 DoF per hand x 2 + 4 DoF per leg x 2) and the action space is much more diverse.
Humans can walk forward, backward, sideways, climb mountains, walk up/down hills, run, handle wet floors or snow, and so on.
The Data Bottleneck
There is simply no internet dataset for actions nor is there the incentives to build one. To put things into perspective: Common rawl for text is on the order of 1.2T tokens, and its rumored that GPT4 was trained on around 13T tokens.
Depending on how you measure it, the entire internet is around 30T tokens. On the other hand, PI-0 a leading robotic foundation model by a top-tier talent group is trained on 903M time-steps across 68 tasks which could be estimated at roughly 250B tokens. And it’s not using human dexterity nor walking and it’s very far from generalization!
This is not discussing how much time and effort that was put in to collect action demonstrations, which is much more challenging than scraping the web.
Moreover, it’s unclear if all problems will be solved by just collecting human demonstration datasets, because its the equivalent of a human watching the same movie 100 times and predicting what will happen if someone asks them what happens after this X scene? Now imagine someone changes the script, humans will have no idea what will happen next! Yet this is how our models are being trained as of now.
So not only is it very expensive and challenging to collect a diverse action dataset, it’s unclear what we want to do with it!
Also, behaviour cloning applied to the physical world hit saturation pretty quickly i.e. more demonstrations doesn’t mean better performance:
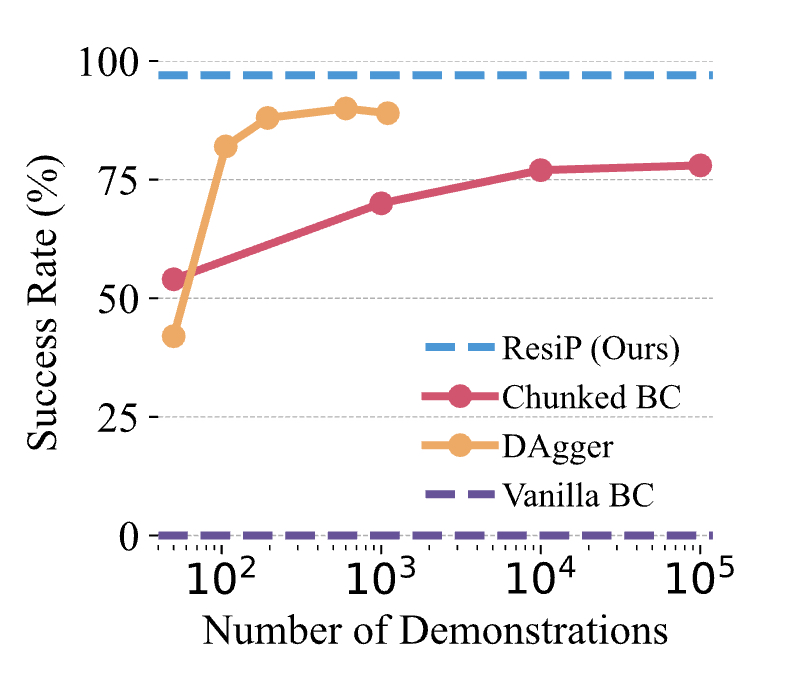
So some kind of data scaling laws for robotics is critical to figure out, and has been discussed by companies like 1X tackling consumer tasks like homes after hitting saturation from factory data really quickly (due to the repetitiveness of the tasks and the structured environment of a factory).
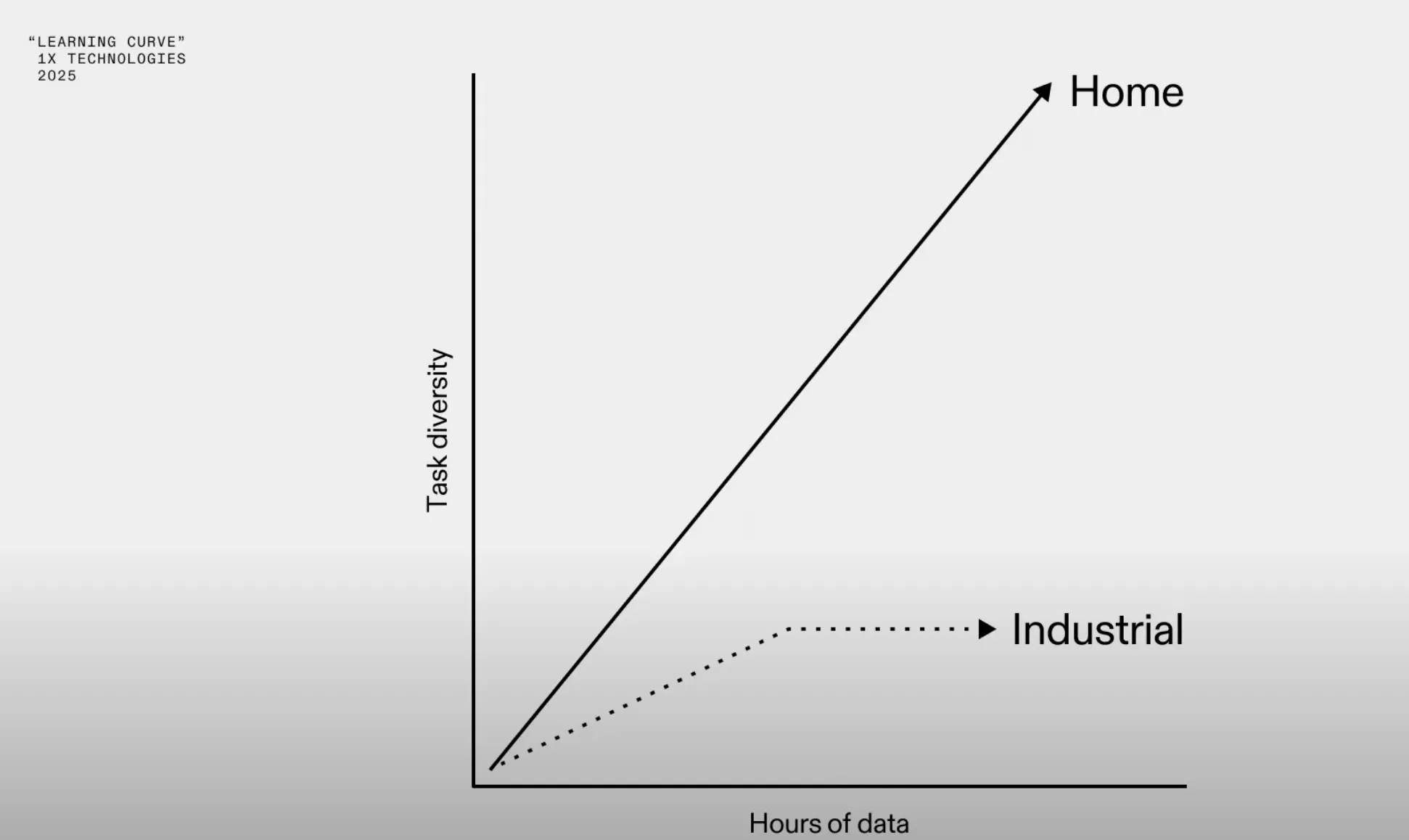
Example questions to motivate scaling laws: how many demonstrations do we need to collect for a task to know its enough? what kind of tasks?
If you’re still not convinced, these are two thought experiments that hopefully will make my point clearer:
Thought experiment I
Imagine you have a million humans walking on a street, and you were able to collect all of that data and train a robot to learn how to walk. It’s probably doable, but if you knock the robot off a bit it will fall. Because how much data will we have around falling? Probably not enough!
Babies barely fall but learn how to walk very efficiently and have amazing mechanisms to recover. Therefore even if we created a Manhattan project level to collect all kinds of data it’s unclear if it will work in the end.
Imitation does not equal policy learning. Models imitates us using our data without critical thinking that distinctively makes us uniquely human. Imitation is not true learning and understanding.
Thought Experiment II
Tesla has around 5 million robots i.e. 5 million tele-operators that aren’t paid by them that are sending data daily to feed into their data engine. Car is two degrees of freedom, working on flat terrain, task is from A to B, not making object-based contact.
Whereas manipulation you have 10 DoF at least if its one hand, and your objects variety are infinite, your tasks are infinite. How many robot operators do we need to match with the Tesla level?
Even if we recorded all of humans motion for walking and dexterity, we still don’t know how to efficiently train a general purpose model for both walking and dexterity.
Moving Forward
While the data bottleneck represents a significant challenge to build a general purpose robot foundation model, I think there’s a lot of hope and advantages that we have compared to tackling this had we not solved unsupervised learning for text and images.
Let’s take a step back and think about what training an AI model really is by reviewing this quote from the excellent blog “The “it” in AI models is the dataset” by James Betker:
Model behavior is not determined by architecture, hyperparameters, or optimizer choices.
It’s determined by your dataset, nothing else. Everything else is a means to an end
in efficiently delivery compute to approximating that dataset.
We have something going for us is that Vision-Language-Actions (VLAs) models like GROOT or OpenVLA are using a VLM backbone that’s already pre-trained on the internet.
As Ilya Sutskever once said in an interview with Jensen about how LLMs are able to learn physical concepts from text:
Even though a text-only neural network has never seen a photon, it can still
learn that "red is more similar to orange than to blue" or "blue is more similar
to purple than to yellow."
He attributed this to the fact that information about the world, including visual concepts, “slowly leaks in through text”. Though not as efficiently as through direct sensory experience, but with enough text, a lot can still be learned!
With both of these ideas in mind, it might be the case that we’re a lot closer to solving physical intelligence than we might realize and that an effective general reward model for the physical world plus sample demonstrations might be sufficient to build a general purpose robot model.
Reward Models for Actions
I think the first production scale example of this is the DYNA-1 model from Dyna that have trained a reward model that is used to give feedback to their manipulation policy:
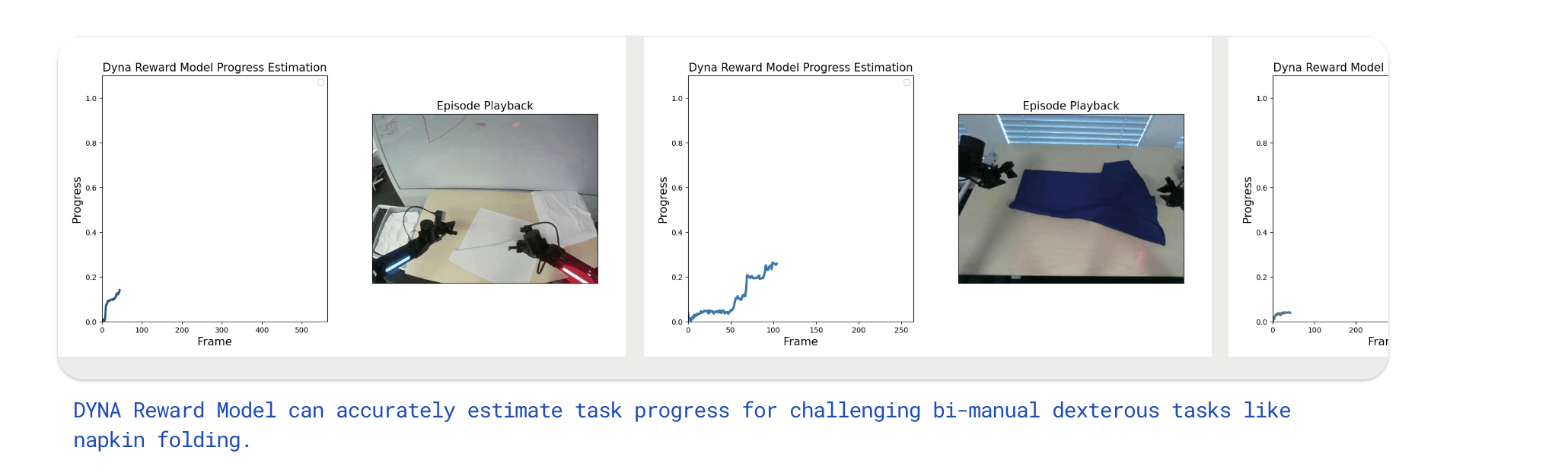
Reward models might be the most general on-policy RL approach to teach robot foundation models how to generalize to the real world and learn from mistakes quickly.
Hypothesis: if we can train a generalized reward model to do RL training for
dexterity, can we do the same for bipedal walking?
If so, can we train a superset reward model for all human actions?
So far there’s a lot of convergence in terms of the training recipes from LLMs to robot foundation models in terms of the unsupervised pre-training phase and post-training via RL, and maybe building a general reward model for actions can help solve the data bottleneck and help models learn more effectively from small demonstrations just like humans!
Notes
-
https://syncedreview.com/2019/02/22/yann-lecun-cake-analogy-2-0/ ↩
-
for the scope of this blog we’ll focus on embodied AI in the physical world, but if you’re interested in digital embodiment checkout the VideoGame Bench ↩