π-0.5: A Foundation Model for Robot Manipulation
Impressive progress and results with the new π-0.5 model from physical intelligence towards building a general purpose foundation model for manipulation!
Following is a quick summary and takeways:
Overview
- focus on generalization to new environments and scene understanding on out of distribution homes => improvements on semantic understanding of VLAs
- not focused on complex dexterity (more on that later)
- tackling homes as the real world benchmark due to high diversity of scenes compared to factories
- excellent performance on relatively complex instructions that require accurate control precision (ex: putting items in drawer, putting towel on oven) which reflects a strong architecture that can balance planning and control
- improved intuition about receiving a detailed instruction, breaking it down into small sub-tasks (task planning) and execution
Data
- empirical study on the data composition to create the right curriculum to teach VLAs to perform tasks in generalized environments
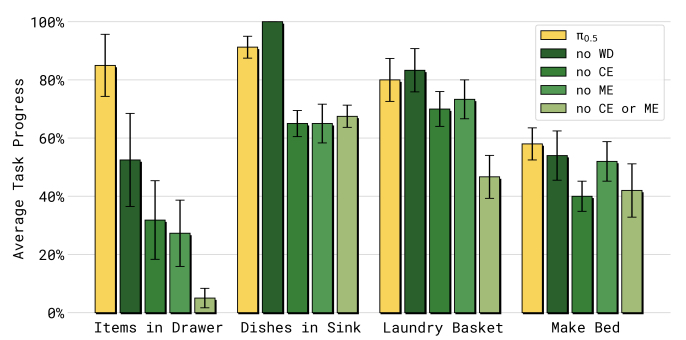
- confirms the importance of web-data (WD) for semantics understanding, cross-embodiment data (CE) and multi-environment data (ME) improve generalization and beat specialized models (on par with RT-2/RT-X takeaways)
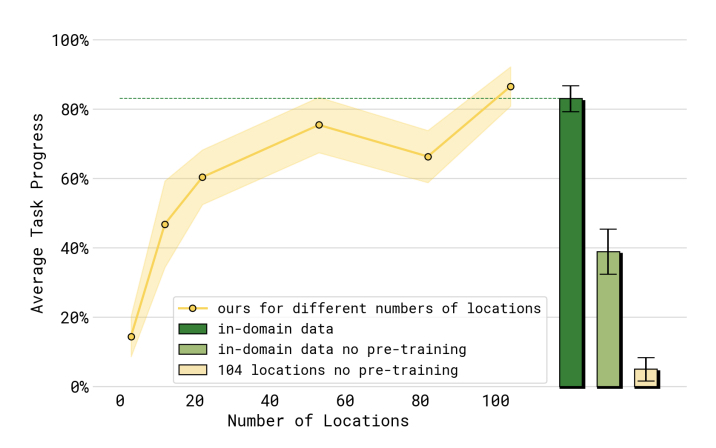
- emperical scaling laws on number of locations diversity to improve performance and flattens near 100 distinct training environments
- this confirms that scaling laws for robots will look different than LLMs [^1] (i.e. mere quantity increase != generalization, scene diversity increase up to a limit = generalization)
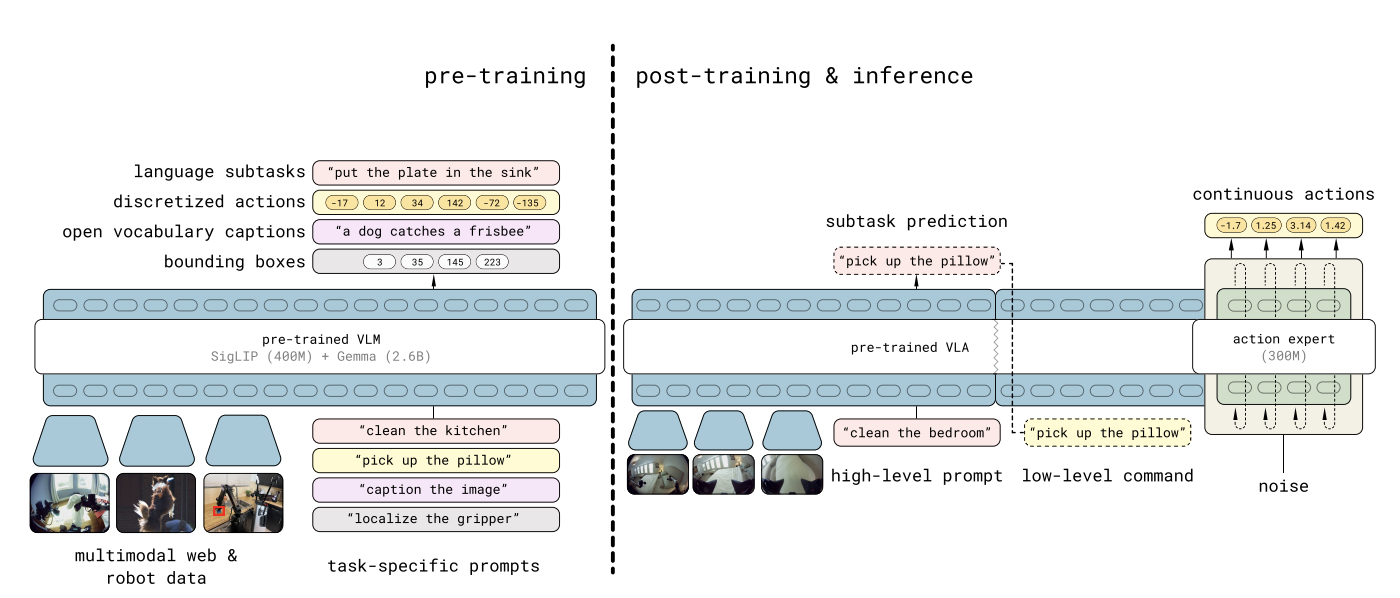
Training
- based on π0, but co-trained on high-level planning and low-level control (doubling down on the system 1/system 2 architecture of VLAs) in a chain-of-thought fashion which improves performance significantly.
- discrete auto-regressive token decoding for high-level actions, continuous flow-matching for low-level motor commands
Performance
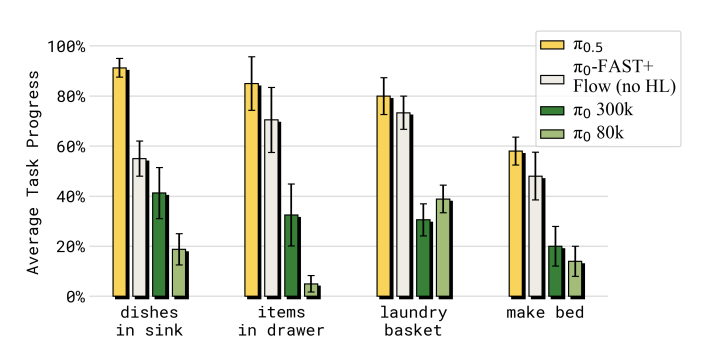
- outperforms π0-FAST+Flow on both generalization and complex instruction following/long horizon tasks
- tasks commentary: putting dishes in sink shows impressive understanding of what objects belong to the category vs. already clean, ability to perform consecutive tasks for 10 mins that might take humans about 3mins (room for speed improvements in executing long horizon tasks)
- reactive policies: can handle interference to the scene, adapt to new environments and still follow initially tasked instruction (ex: interruption to putting laundry in basket) => robot doesn’t always get stuck in demonstrations and is able to complete tasks.
- can follow high level tasks and detailed instructions
Un-Explored Tasks
- would be impressive to include clarification questions as part of the chain of thought of task execution. For example if the goal was to put clothes in the top drawer and the drawer was full, the robot would ask humans for their preference on where to place it or experiment with opening other drawers to see if the object fits in or not to the category of the drawer.
- bring more LLMs practices like asking clarifying questions before executing tasks to understand user intention before starting execution.
- tasks that require complex and long reasoning: make a wood-oven margherita pizza Naple style and robot has to use ingredients and go through longer horizon tasks on the order of 30mins with detailed sub-tasks that all add up to either a good michelin star pizza or no
Takeaways
- As demonstrated by the co-training and data diversity results, tackling consumer tasks in homes is the problem space to tackle vs. factories (on par with strategy at 1X [^2])
- Orgs can that can build a data engine of large fleet of robots collecting data from the real world consumer tasks will be able to improve generalization and performance much faster than those who don’t
- Baking chain-of-thought reasoning, planning and control, and data diversity improve generalization and complex task following
- Trying to solve generalization pushes the frontier vs. overfitting for repetitive specialised tasks/robots [^3]
- π-0.5 serves as a SoTa foundation model for fine-tuning for specific medium-horizon tasks that can generalize to new environments
- Data scaling laws for robot learning remains an open problem with good intuitions based on empirical data about what makes a good data backbone, but the field is still lagging on quantifying it and predicting performance before training
Speculations for π-1
Just like the move from gpt-2 to gpt-3 wasn’t about scaling data/model size only per say, but rather a qualitative shift in the auto-regressive modelling paradigm – the following are some thoughts about what would it take to move towards a new paradigm of the π-series towards a general purpose model for manipulation:
- tackling more complex dexterous tasks like bi-hands: given the complexity of this problem in terms of degrees of freedom and motion control, this will provide strong feedback signals to build a generalized model that can both plan and execute low-level control policies at human level speed for manipulation
- training towards much longer horizon tasks like cooking meals that require detailed accurate sub-tasks and getting them all right together result in either a good outcome or not