Deep Learning for Multi-Robot Motion Planning
This was my master’s research thesis at the Rainbow team, Inria Rennes, France during the lovely covid period from 12/2020 into 08/2021.
Introduction
Large-scale swarms are composed of multiple agents that collaborate to accomplish a task. In the future, these systems could be deployed to, for example, provide on-demand wireless networks, perform rapid environmental mapping, search after natural disasters, or enable sensor coverage in cluttered and communications-denied environments.

Effective communication is key to successful, decentralized, multi-robot path planning. Yet, it is far from obvious what information is crucial to the task at hand, and how and when it must be shared among robots.
The manner in which information is shared is crucial to the system’s performance, yet is not well addressed by current machine learning approaches.
Motivation
Centralized controllers based on classical control theory algorithms suffer from several inefficiencies, like computational complexity, scalability issues, and most importantly, their robustness to any failures with the centralized controller.
To tackle this problem, we took a different approach utilizing learning-based algorithms and deep neural networks to develop a decentralized controller.
We developed a scalable deep learning model powered by graph neural networks and reinforcement learning, that with the right training tricks has proven to outperform the traditional centralized controller’s approach.
Imitation Learning
In order to mimic centralized expert algorithms, yet benefit from the power of decentralized controllers we used imitation learning (IL) in its simplest form, behavioral cloning.
I won’t go deep into what imitation learning is or the theory behind it inside this blog (you can read my thesis for more on IL), but briefly inspired by the paper cited below from Nvidia we imitated an expert centralized controller and trained our GNN model on the data collected from it (more on this below).
Behavioral Cloning

To prove our approach is worthy, we chose a famous problem in the multi-robotic space called “consensus”. We ran 100s of episodes with different initial conditions for a collection of robots that use a traditional centralized controller for consensus and trained our GNN model on this data in a supervised-learning approach.
GNN Model Architecture
While designing our neural network, we conducted dozens of experiments and iterations to come up with the final design that entails smart engineering tricks to make our model work.

This GNN model was developed using PyTorch, which can be used by each robot independently in a decentralized manner, which is very powerful compared to a single centralized controller.

Note how the controller inputs for each robot are just the adjacency matrix representing the communication topology of the network, and the positions of neighboring robots that can smoothly be computed in a decentralized manner.
This GNN model predicts the local control inputs for each robot, based on its independent measurements of its surroundings.
Experiments Setup
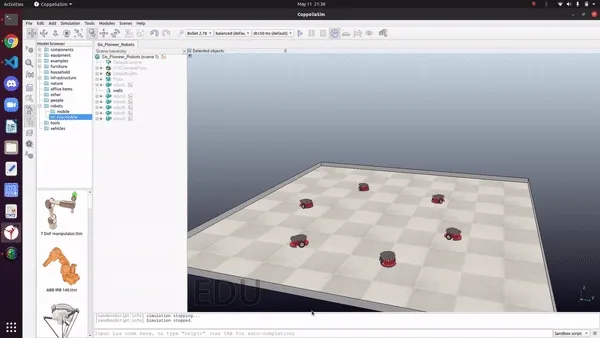
Due to some restrictions and available resources, we chose to start our work inside V-Rep (now known as CoppeliaSim) which is a robotics simulator.
Summary
Basically as a short summary, we:
- Collected/cleaned/transformed data features using NumPy & Pandas.
- Developed & trained deep learning models using PyTorch on CUDA/52 clustered GPUs running docker containers.
- Deployed models in real-time using APIs on CoppeliaSim.
- Integrated different software components using ROS2 to control the robots. Inside CoppeliaSim, we integrated ROS2 within our Python code in order to publish speeds and subscribe to the poses of each robot. Source code and steps to replicate our work can be found here.
Consensus Algorithm
As mentioned above, we chose consensus at the beginning to prove that our approach actually works, since consensus is a relatively easy problem for the multi-robot motion planning problem. Once we proved that our model works, we then refactored our GNN model to solve different types of motion planning problems.
Algorithm
Below is the consensus algorithm we used as a centralized controller to collect data from:

Demo
Below is a short demo of running the centralized consensus algorithm on a fleet of six pioneer robots inside CoppeliaSim:
We had to do some math derivations and control theory work to make it easy to control these robots, as well as some parameter tuning.
Data Collection
In order to collect data from the so-called expert algorithm, we wrote a python script that generates random scenes for the initial positions of the robot, and then would run consensus in each episode and collect all the meta-data necessary to train our model.
Below is a short demo of how this script works and collects data:
The scale of datasets we collected is up to a 100k data samples per network topology. Another important note to mention in our data collection and experiments setup is that we used several different graphs (fully connected, cyclic, weakly connected graphs, etc) in order to demonstrate how well our developed GNN model works with different topologies.
More on this in the results section below.
Decentralized Deep Learning Model in Action
We trained our GNN model on a dataset composed of several different network topologies and graphs, collected from the consensus controller. Below is a short demo of running consensus using our decentralized GNN model:
After proving that our method works using imitation learning, it occurred to me while discussing with my advisor Gennaro Notomista that reinforcement learning seems like a perfect way to push our model performance forward due to reasons I will mention briefly in the next section.
Reinforcement Learning
In order to improve the performance of our proposed GNN model training it using reinforcement learning was an obvious next move for me. Since the reward function for the consensus algorithm of multi-robots can be derived by hand easily, and also exposing the network to a lot of different graph topologies will practically expose the GNN model to more diverse, bigger data distributions: integrating the GNN inside the DQN model would be a great next step to improve the performance of our model.
There are other possible reinforcement learning algorithms to be used for our setup, however due to time constraints and the limited computing resources we had we stook with only using Q-Learning to train our model further.
Custom Gym Environment
In order to train our robots using Deep Q-Learning, we created a custom agent environment from scratch using Gym from OpenAI and integrated it with V-Rep.
This took us some to develop and get stable results (all code is open-sourced!).
We set up the environment in a way that only one robot (i.e. our agent) uses our developed GNN model as the deep neural network in the DQN framework, while the rest use the centralized controller to perform consensus. And thus, the GNN model will be trained using RL to generalize to more complex topologies.
Deep Q-Learning
The DQN (Deep Q-Network) algorithm was developed by DeepMind in 2015. It was able to solve a wide range of Atari games (some to superhuman level) by combining reinforcement learning and deep neural networks at scale. The algorithm was developed by enhancing a classic RL algorithm called Q-Learning with deep neural networks and a technique called experience replay.
Below is how we integrated our GNN model into DQN and formulated the problem into your traditional action/state/reward reinforcement learning setup.
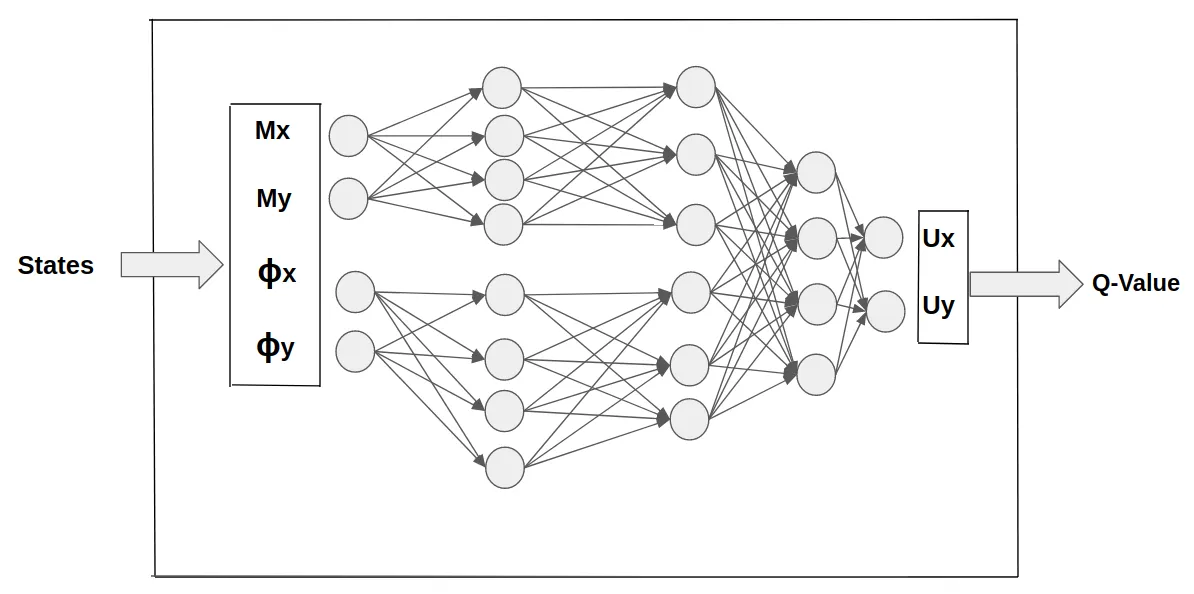
Usually, DQN models have an embedded neural network within them, and so we just integrated the developed GNN model and trained it instead.
Results
I’m not going to list all the separate experiments and results we got here to avoid overloading this blog but feel free to go over my thesis for more information.
These are the following experiments we ran: 1) Fully Connected Graph 2) Cyclic Graph 3) Line Graph 4) Random Weak Graph
To summarize, our model outperformed the centralized controller for the fully connected graph, as well as with weaker communication topologies.
Conclusion
The main objective of this thesis was to propose a decentralized data-driven control strategy for multi-robot motion planning.
We built a scalable deep learning framework powered by graph neural networks & reinforcement learning to solve this problem, and demonstrated its efficiency on consensus.
This model has been later deployed to solve different types of motion planning problems in a decentralized fashion.
Acknowledgements
Special thanks to Claudio Pacchierotti for giving me the chance to join his team, Gennaro Notomista, and Marco Cognetti for mentoring me throughout this project, and for whom this work would’ve been impossible to achieve. Forever grateful!
This work is the result of almost a year of effort spanning from Europe to Canada, late nights, early mornings, weekends, and even holidays collaborations.
I will always remember this project, due to the uncountable doors it opened for me as I graduated and the spark it gave my career moving forward. Cheers!
Misc
It’s challenging to dive into the details of this project inside one blog, therefore I advise readers to read my master thesis and code if interested in learning more.